Processing Features
Video Decoding
When dealing with video processing, whether it involves live video streams or post-processing of recorded video, all pipelines commence with the first step of Video Decoding.
In this stage, the Video Processing Platform takes the incoming video stream and converts it into individual frames which are further processed by detection algorithms and neural networks. For real-time streams or video files, this conversion is performed continuously during the whole footage.
Detection
Detection is the process of finding objects in an entire incoming frame. Video Processing Platform provides the detection of faces, pedestrians, and common objects.
For video streams, the Video Processing Platform performs detection on incoming frames periodically with a specified time interval. This interval is usually bigger than the interval between frames, so the system doesn’t detect faces, pedestrians or common objects in every incoming frame within the video stream. This is because the process is very consuming in terms of computing resources.
For uploaded static image files, Video Processing Platform is performing detection on every incoming frame.
When Video Processing Platform detects an object (face, pedestrian or common object), the system creates a cropped image of the found object. Depending on the settings, Video Processing Platform stores the cropped image in the database, and optionally also the full frame.
In Video Processing Platform, a pedestrian entity represents one pedestrian detected in a single frame, a face entity represents one face detected in a single frame and a common object entity represents one common object detected in a single frame.
One single frame may have one or multiple faces detected, one or multiple pedestrians detected, and one or multiple common objects detected, in other words, one single frame may result in one, two or even tens of detections.

Incoming frame - Face detection

Incoming frame - Pedestrian detection
Face Detection
Face detection on a frame is performed by the Face Detector usually referred to as the Detector. For Live Video Processing the face detection is configured on a Camera level (each camera may have a different configuration, please see also the camera settings via the Video Processing Platform Station) and the following configurations are available.
Confidence Threshold
The face detection confidence threshold is a parameter used in face detection algorithms to control the sensitivity and accuracy of the face detection process. The confidence threshold is the minimum confidence score required for a detected object to be considered a valid face detection.
The score is typically a value between 0 and 10,000, where 0 means low confidence (unlikely to be a face) and 10,000 means high confidence (highly likely to be a face). The default value is 450 and confidence 3,000+ is considered a safe value.
By setting a confidence threshold, you can control the trade-off between sensitivity and accuracy in face detection. A higher threshold will result in fewer false positives (non-faces being detected as faces) but might also miss some actual faces, making it less sensitive thus introducing false negatives. On the other hand, a lower threshold will be more sensitive, but it may also include more false positives.
Face Size Range
By setting the Minimum and Maximum Face Size you can effectively control how small or how large faces are detected. Faces with less than 25px have poor biometric quality. Generally, the suggested face size is 30 or more. For more information about the face size read here.
Face Detector Resource ID
Face detection can be performed via several ways. Whether on CPU or hardware accelerated on GPU, in Camera service or dedicated service, and can be performed using different algorithms. All this is operated with a single configuration property faceDetectorResourceId.
Remote vs In-Proc Detection
The suffix _remote in the faceDetectorResourceId stands for remote processing.
CPU vs GPU Detection
The cpu stands for CPU processing, gpu stands for GPU processing, any means any available detection resource.
Balanced vs Accurate Algorithm
The prefix accurate_ means Accurate detection algorithm. The default one is Balanced.
| value | description |
|---|---|
| none | Face Detection is disabled |
| cpu | in-proc detection using default Balanced detection algorithm on CPU |
| gpu | in-proc detection using default Balanced detection algorithm on GPU |
| accurate_cpu | in-proc detection using Accurate detection algorithm on CPU |
| accurate_gpu | in-proc detection using Accurate detection algorithm on GPU |
| cpu_remote | dedicated process detection using default Balanced detection algorithm on CPU |
| gpu_remote | dedicated process detection using default Balanced detection algorithm on GPU |
| any_remote | dedicated process detection using default Balanced detection algorithm on any available processing unit (CPU or GPU) |
| accurate_cpu_remote | dedicated process detection using Accurate detection algorithm on CPU |
| accurate_gpu_remote | dedicated process detection using Accurate detection algorithm on GPU |
| accurate_any_remote | dedicated process detection using Accurate detection algorithm on any available processing unit (CPU or GPU) |
Face Mask Detection
Video Processing Platform also extracts information if a detected person wears a face mask and also provides the information if the face mask is worn properly. The information is provided in three attributes – FaceMaskConfidence, NoseTipConfidence and the calculated enumeration FaceMaskStatus.
Face mask attributes
FaceMaskConfidence – The confidence that a mask is present. It is a decimal number in the range [-10,000 to 10,000]. A higher number represents a higher confidence that the mask is present.
NoseTipConfidence – The attribute determines if the face mask is worn properly, i.e. that the nose is completely covered. It is a decimal number in the range [0 to 10,000]. A higher number represents more confidence that the nose tip is visible.
FaceMaskStatus – The enumeration determines if the mask is present on the face. The enumeration has the values Mask, NoMask or Unknown. It is calculated from the FaceMaskConfidence attribute using the FaceMaskThreshold property of FaceMaskConfidenceConfig.
The attributes are extracted from the face along with the age and gender attributes.
Availability
The face mask detection attributes are available on Face and MatchResult entities in:
Limitations
Currently face mask detection is not available for the fast detection option.
Face mask detection was also not available for all faces created before face mask detection was implemented in Video Processing Platform. For these faces, FaceMaskConfidence and NoseTipConfidence will have the value null and FaceMaskStatus will be Unknown.
Face extraction
Extraction is a process of conversion of face features from the acquired digital image into a binary representation of the face, which is called a biometric template. Put simply, extraction is the process of generating a biometric template from the provided image.
In Video Processing Platform, a template is generated from every detected face.

Generating the template
Biometric templates enable us to compare image data extremely fast and use the matching and grouping functionality.
In addition to the template, Video Processing Platform extracts various attributes, such as age, gender and additional information such as the detection quality, coordinates of the face on the frame, position of the head defined by roll, pitch and yaw angles, etc. Video Processing Platform also provides information on whether the detected person wears a facial mask.
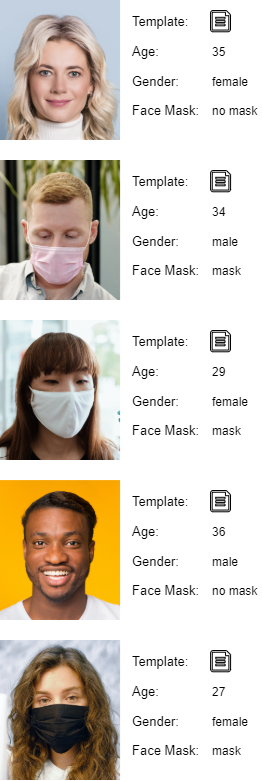
Example of attributes extracted from the face image
Face matching
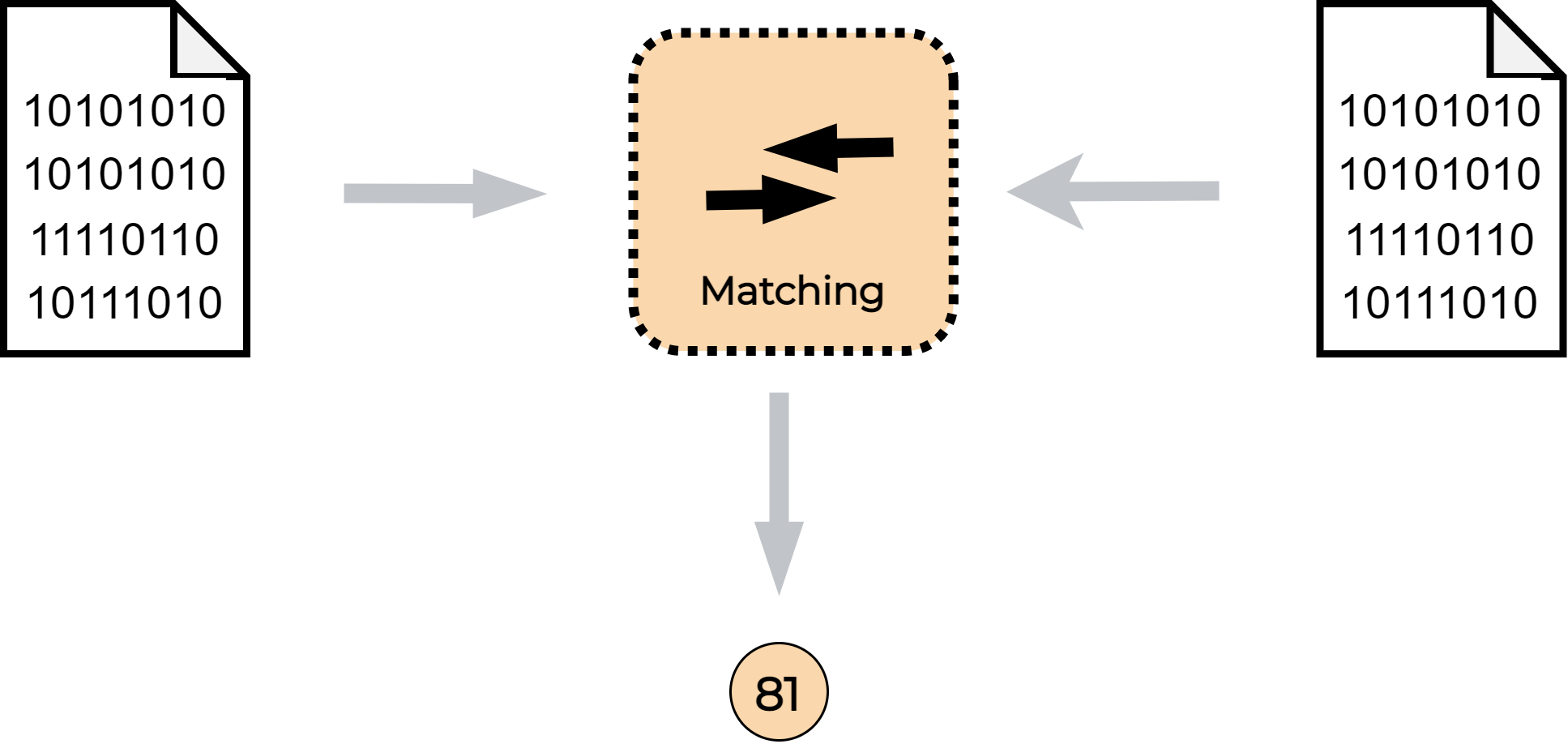
Matching is a comparison of two biometric templates. The result of the comparison is a matching score.
The matching score of the two biometric templates represents a degree of similarity between these templates. In the Video Processing Platform, matching is performed when a detected face is being identified against people registered in a watchlist.
Video Processing Platform allows you to create multiple watchlists and easily register people (watchlist members) in them. You can register watchlist members by uploading their face image together with their name and other information. During the registration of a member in a watchlist, Video Processing Platform automatically generates a biometric template from the provided image. This template is used for identification in the matching process.
Templates are also automatically generated from faces detected on live video streams and uploaded videos. These generated templates are automatically compared (matched) against all templates previously registered in all your watchlists. Video Processing Platform can perform thousands of comparisons within a few milliseconds. Therefore, you can register thousands of watchlist members and the identification will still take just a few milliseconds.
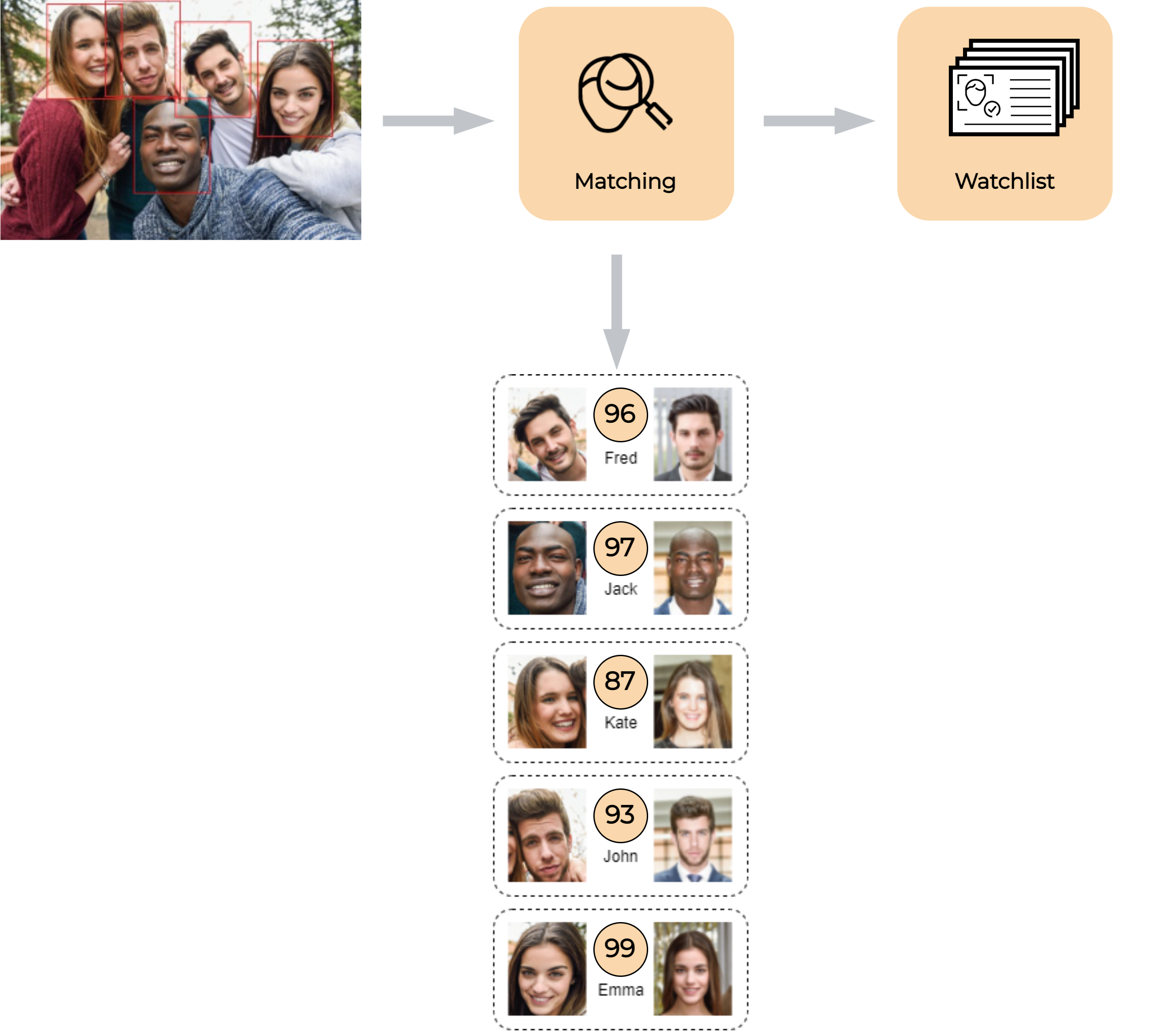
Matching is automatically executed on live video streams and uploaded videos. By default, matching isn’t executed on images. However, it is possible to manually perform matching on uploaded images through the REST API.
Matching score
During matching, a detected person is automatically compared with all persons already registered in watchlists. The result of the face template comparison (matching) is a matching score ─ the higher the score, the higher the similarity of the two compared faces. In the Video Processing Platform, the matching score can have a value between 0 and 100.
Matching threshold
Video Processing Platform decides whether the compared persons are matched or not based on a user-defined threshold for the matching score. The matching score that is equal to or above the defined threshold is considered a match. Any matching score below the matching threshold value is considered a no-match. In case when a person matches with multiple watchlist members only the highest score is considered as a match. The default value for the threshold in the Video Processing Platform is 40.
In the following example, Video Processing Platform compares face templates of detected persons with templates from the watchlist. The decision if these pairs are a match or a no-match, depends on the value of the matching threshold. In this case, the user chose the threshold value of 40. Compared face templates with matching scores 85 and 78 are considered as matches. Compared face templates with the matching scores 38 and 12 are considered as no-matches.
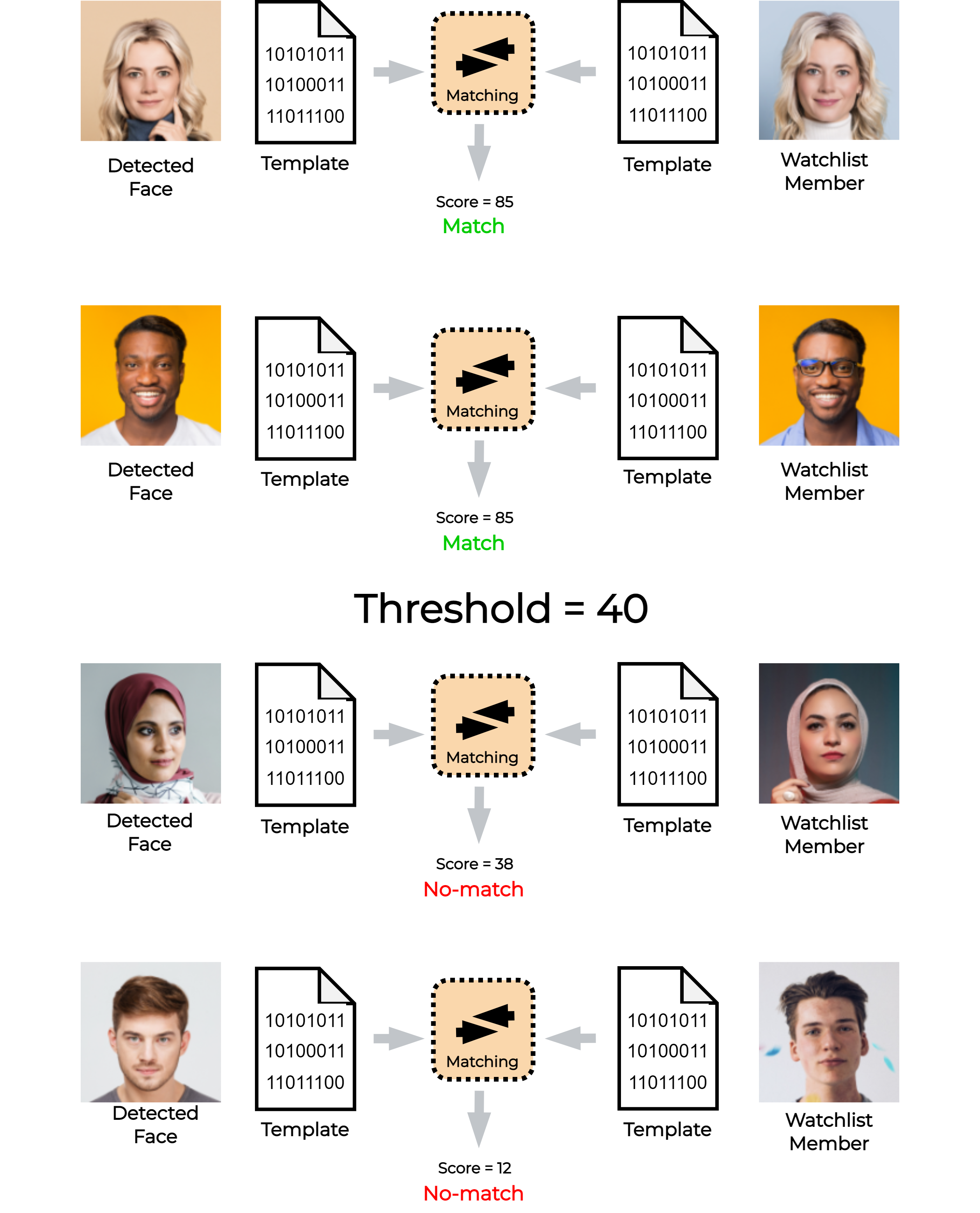
Finding the right value for the threshold can vary from case to case, as it depends on several aspects like the size of the watchlist, quality of the detected faces, size of the detected faces, etc. Therefore, we recommend performing some fine-tuning to set the right value for your use case.
Please consider these factors when setting a value for the matching threshold:
| Treshold value | Pros | Cons |
|---|---|---|
| Higher | Higher security, because of the lower rate of false match. | Can cause too strict security, as only high-quality images will be matched. As a result, Video Processing Platform may conclude that a person doesn't match their enrolled image in the watchlist even if they actually do. |
| Lower | Higher convenience, because of the lower rate of false reject. | Can cause lower security, because of a higher rate of falsely matched persons. As a result, Video Processing Platform may conclude that a person matches an enrolled image in the watchlist even if they actually don't match. |
Similar system of matching is used for additional modalities, such as the palms and QR codes.
Palm detection
In the version v5_4.29.0 new Palm modality was added. When enabled, the palms can be detected and used for 1:N identification. This applies to LFIS, RTSP and Edge camera inputs.
Palm detection on a frame is performed by the Palm Detector usually referred to as the Detector. The image of a detected palm is then sent into Palm Extractor that creates a template. Such template then can be subject of the Matching similarly as the Face Matching. The palms have their own matching thresholds defined for each Watchlist.
QR code detection
Visual Codes are new modality added in the version v5_4.28. This brings Identification based on Time-based One Time Password encoded in QR code (QR TOTP).
New REST API endpoints were added to LFIS and the REST API: an API endpoint for creating TOTP secrets for watchlist members and a conditionally enabled endpoint displaying currently valid QR code for watchlist member with enabled TOTP. The Video Processing Platform Station allow you to enable TOTP codes for each Watchlist member and brings the QR codes directly.
Pedestrian detection
An optional pedestrian detection on a frame is performed by the Pedestrian Detector. This feature is not available for the Rapid Video Processing. When Video Processing Platform detects a pedestrian, the system creates a cropped image of the found object, sends a notification and depending on the settings, saves information about the pedestrian into a database.
Information about detected pedestrians is also available via the API endpoints, you can use either REST API or GraphQL API.
Pedestrian attributes extraction
In addition to pedestrian detection, the Video Processing Platform provides advanced functionality to extract valuable attributes of detected pedestrians. This chapter will guide you through the process of leveraging the Video Processing Platform’s capabilities to extract and store pedestrian attributes.
System configuration
By configuring the system and utilizing services and REST APIs, you can access valuable information about detected pedestrians and integrate it into your workflow.
Service for pedestrian attributes extraction
The Video Processing Platform utilizes the RpcPedestrianExtractor service for extracting pedestrian attributes. This service supports various resources such as: cpu, gpu, and any routing.
The Video Processing Platform sends requests with a pedestrian crop image, the service returns the extracted attributes based on the service’s configuration. All attributes obtained through the service are stored in the database and included in the PedestrianInsertedNotificationDTO for further use and integration.
REST API
To configure the pedestrian attributes extraction, you can utilize the REST API provided by the Video Processing Platform, using endpoint PUT /api/v1/Cameras on your REST API port 8098.
By accessing the pedestrianExtractorResourceId parameter within the Camera entity, you have control over enabling or disabling attribute extraction and specifying the desired resource to be utilized. Valid options for pedestrianExtractorResourceId include cpu_remote, gpu_remote, any_remote. These values determine the resource allocation for the attribute extraction process.
Pedestrian attributes and interpretation
We recognize two types of attributes:
confidence attributes - raw attributes directly returned by the underlying attribute extractor. The confidence values associated with these attributes are mapped to a range of
0to10,000.interpreted attributes - derived from confidence attributes through the evaluation of a confidence threshold or by combining multiple attributes.
Confidence attributes
Below you will find a list of supported confidence pedestrian attributes. Each value represents a confidence of the self-explaining attributes of the particular pedestrian.
| Attribute name | Value type | Value range |
|---|---|---|
| HatConfidence | float | <0 - 10,000> |
| GlassesConfidence | float | <0 - 10,000> |
| ShortSleeveConfidence | float | <0 - 10,000> |
| LongSleeveConfidence | float | <0 - 10,000> |
| UpperStripeConfidence | float | <0 - 10,000> |
| UpperLogoConfidence | float | <0 - 10,000> |
| UpperPlaidConfidence | float | <0 - 10,000> |
| UpperSpliceConfidence | float | <0 - 10 000> |
| LowerStripeConfidence | float | <0 - 10,000> |
| LowerPatternConfidence | float | <0 - 10,000> |
| LongCoatConfidence | float | <0 - 10,000> |
| TrousersConfidence | float | <0 - 10,000> |
| ShortsConfidence | float | <0 - 10,000> |
| SkirtOrDressConfidence | float | <0 - 10,000> |
| BootsConfidence | float | <0 - 10,000> |
| HandBagConfidence | float | <0 - 10,000> |
| ShoulderBagConfidence | float | <0 - 10,000> |
| BackpackConfidence | float | <0 - 10,000> |
| HoldObjectsInFrontConfidence | float | <0 - 10,000> |
| SeniorConfidence | float | <0 - 10,000> |
| IsAdultConfidence | float | <0 - 10,000> |
| IsChildConfidence | float | <0 - 10,000> |
| FemaleConfidence | float | <0 - 10,000> |
| FrontConfidence | float | <0 - 10,000> |
| SideConfidence | float | <0 - 10,000> |
| BackConfidence | float | <0 - 10,000> |
Interpreted attributes
Below you will find a list of supported interpreted pedestrian attributes. Each interpreted value states whether the confidence of each of the self-explaining attributes is interpreted as true or false.
| Attribute name | Interpreted by | Value type | Interpreted value |
|---|---|---|---|
| Hat | CommonThreshold | bool | True/False |
| Glasses | GlassesThreshold | bool | True/False |
| ShortSleeve | CommonThreshold | bool | True/False |
| LongSleeve | CommonThreshold | bool | True/False |
| UpperStripe | CommonThreshold | bool | True/False |
| UpperLogo | CommonThreshold | bool | True/False |
| UpperPlaid | CommonThreshold | bool | True/False |
| UpperSplice | CommonThreshold | bool | True/False |
| LowerStripe | CommonThreshold | bool | True/False |
| LowerPattern | CommonThreshold | bool | True/False |
| LongCoat | CommonThreshold | bool | True/False |
| Trousers | CommonThreshold | bool | True/False |
| Shorts | CommonThreshold | bool | True/False |
| SkirtOrDress | CommonThreshold | bool | True/False |
| Boots | CommonThreshold | bool | True/False |
| HandBag | CommonThreshold | bool | True/False |
| ShoulderBag | CommonThreshold | bool | True/False |
| Backpack | CommonThreshold | bool | True/False |
| HoldObjectsInFront | HoldThreshold | bool | True/False |
| IsSenior | Will be present if is MAX(IsSenior, IsAdult, IsChild) | bool | True/False |
| IsAdult | Will be present if is MAX(IsSenior, IsAdult, IsChild) | bool | True/False |
| IsChild | Will be present if is MAX(IsSenior, IsAdult, IsChild) | bool | True/False |
| IsMale | MaleConfidence is calculated as inverse confidence to female: (10,000 - FemaleConfidence) then regular CommonThreshold is applied | bool | True/False |
| IsMale | CommonThreshold | bool | True/False |
| Front | Will be present if is MAX(Front, Back, Side) | bool | True/False |
| Side | Will be present if is MAX(Front, Back, Side) | bool | True/False |
| Back | Will be present if is MAX(Front, Back, Side) | bool | True/False |
Threshold Interpretation formula
There are 3 possible outcomes of threshold evaluation for interpreted attributes
If the confidence value is above the upper threshold → TRUE
If the confidence value is below threshold → FALSE
If confidence value is between low and upper threshold → Indecisive (attribute will never be included in response)
Pedestrian attributes configuration
Video Processing Platform allows you to configure which attributes should be returned by the extractor and also thresholds for interpretation in RpcPedestrianExtractor. The configuration while has the same content is done differently in a Windows and a Docker installation.
Windows installation
The Default configuration is as follows and can be found in appsettings.json for the Windows installation.
"Extraction": {
"Attributes": {
"AppendInterpretedAttributesUnderLowerThreshold": false,
"AppendConfidenceAttributes": false,
"AppendInterpretedAttributes": true,
"InterpretationThresholds": {
"CommonThresholdUpper": 8000,
"CommonThresholdLower": 4000,
"GlassesThresholdUpper": 8000,
"GlassesThresholdLower": 4000,
"HoldThresholdUpper": 7000,
"HoldThresholdLower": 3000
}
}
}
For more information about updating the appsettings.json files click here.
Docker installation
For the Docker setup, please add the environmental variables for the pedestrian-extractor service in the docker-compose.yml file:
- Extraction__Attributes__AppendInterpretedAttributesUnderLowerThreshold=false
- Extraction__Attributes__AppendConfidenceAttributes=false
- Extraction__Attributes__AppendInterpretedAttributes=true
- Extraction__Attributes__InterpretationThresholds__CommonThresholdUpper=8000
- Extraction__Attributes__InterpretationThresholds__CommonThresholdLower=4000
- Extraction__Attributes__InterpretationThresholds__GlassesThresholdUpper=8000
- Extraction__Attributes__InterpretationThresholds__GlassesThresholdLower=4000
- Extraction__Attributes__InterpretationThresholds__HoldThresholdUpper=7000
- Extraction__Attributes__InterpretationThresholds__HoldThresholdLower=3000
The resulting service would look like this:
pedestrian-extractor:
image: ${REGISTRY}sf-pedestrian-extractor:${SF_VERSION}
container_name: SFPedestrianExtractorCpu
restart: unless-stopped
environment:
- RabbitMQ__Hostname
- RabbitMQ__Username
- RabbitMQ__Password
- RabbitMQ__Port
- AppSettings__Log_RollingFile_Enabled=false
- AppSettings__USE_JAEGER_APP_SETTINGS
- JAEGER_AGENT_HOST
- Gpu__GpuEnabled=true
- Gpu__GpuNeuralRuntime=Tensor
- Extraction__Attributes__AppendInterpretedAttributesUnderLowerThreshold=false
- Extraction__Attributes__AppendConfidenceAttributes=false
- Extraction__Attributes__AppendInterpretedAttributes=true
- Extraction__Attributes__InterpretationThresholds__CommonThresholdUpper=8000
- Extraction__Attributes__InterpretationThresholds__CommonThresholdLower=4000
- Extraction__Attributes__InterpretationThresholds__GlassesThresholdUpper=8000
- Extraction__Attributes__InterpretationThresholds__GlassesThresholdLower=4000
- Extraction__Attributes__InterpretationThresholds__HoldThresholdUpper=7000
- Extraction__Attributes__InterpretationThresholds__HoldThresholdLower=3000
volumes:
- "./iengine.lic:/etc/innovatrics/iengine.lic"
- "/var/tmp/innovatrics/tensor-rt:/var/tmp/innovatrics/tensor-rt"
runtime: nvidia
For more information about updating the environment variables for a docker setup, please read here.
Attributes filtering
You can control how many attributes are returned by setting the Append configuration properties.
| Append configuration property | Description |
|---|---|
| AppendInterpretedAttributesUnderLowerThreshold | Returns interpreted attributes that did not pass the threshold evaluation |
| AppendConfidenceAttributes | Return confidence attributes in response |
| AppendInterpretedAttributes | Return interpreted attributes in response |
Thresholds
| Threshold name | Value type | Value range | Default value |
|---|---|---|---|
| CommonThresholdUpper | float | <0 - 10,000> | 8000 |
| CommonThresholdLower | float | <0 - 10,000> | 4000 |
| GlassesThresholdUpper | float | <0 - 10,000> | 8000 |
| GlassesThresholdLower | float | <0 - 10,000> | 4000 |
| HoldThresholdUpper | float | <0 - 10,000> | 7000 |
| HoldThresholdLower | float | <0 - 10,000> | 3000 |
Body parts detection
As of version Video Processing Platform v5_4.26 we do not provide the Body Parts Detection anymore. This feature is deprecated. If more information is needed, please contact us.
Object detection
Object Detection is a cutting-edge computer vision technique that allows Video Processing Platform to detect and recognize animals, vehicles and other common objects within video streams. With this feature, you can leverage the power of artificial intelligence to automatically detect and analyze objects of interest in real-time, opening up a world of possibilities for various applications.
Enabling Object Detection
To enable object detection through the REST API, simply set the value of the objectDetectorResourceId parameter within the Camera endpoint ( PUT /api/v1/Cameras). There are several options available for this parameter, including:
| Value | Description |
|---|---|
none | object detection is disabled |
sfe_object_cpu_remote | object detection utilizing CPU resources remotely |
sfe_object_gpu_remote | object detection utilizing GPU resources remotely |
sfe_object_any_remote | object detection utilizing any available remote resources |
By default, the value is set to none, which means object detection is turned off.
By specifying the appropriate ObjectDetectorResourceId value in your API requests, you can configure the object detection feature to suit your requirements.
Example: Object detection utilizes CPU resources remotely and it is enabled only for the object detection of cars, bicycles, cats and dogs.
"objectDetectorResourceId": "sfe_object_cpu_remote",
"objectDetectorConfig": {
"minObjectSize": 40,
"maxObjectSize": 2000,
"maxObjects": 20,
"confidenceThreshold": 5000,
"objectTypesConfiguration": {
"detectCar": true,
"detectBus": false,
"detectTruck": false,
"detectMotorcycle": false,
"detectBicycle": true,
"detectBoat": false,
"detectAirplane": false,
"detectTrain": false,
"detectBird": false,
"detectCat": true,
"detectDog": true
}
}
Additionally, you can configure also preview bounding box color for detected common objects via objectBoundingBoxColor parameter in the SetupPreview endpoint PUT api/v1/Setup/Preview
{
"faceBoundingBoxColor": "#f58a42",
"pedestrianBoundingBoxColor": "#ffffff",
"objectBoundingBoxColor": "#e638d3"
}
Supported objects
The Smartface Platform supports detection of objects such as vehicles, animals, and other commonly encountered objects:
vehicles: Car, Bus, Truck, Motorcycle, Bicycle, Boat, Airplane, Train,
animals: Bird, Cat, Dog, Horse, Sheep, Cow, Bear, Elephant, Giraffe, Zebra,
other objects: Suitcase, Backpack, Handbag, Umbrella, Knife.
Tracking
Tracking is the process of following the movement of a person within a video stream based on a detected face/pedestrian and object. Video Processing Platform automatically performs tracking on all processed video streams. When a for example a face is detected, tracking follows the movement of the same person in the following frames. All faces detected during the tracking of the same person are stored in a single entity called a tracklet. Such tracklets are created also for pedestrians and objects.
Tracking helps us to know when and where a person entered or left a monitored scene and how long a person spent in the video scene.
![]()
Tracking explained
Both detection and tracking are repeatedly executed.
Video Processing Platform performs detection on an entire frame to detect faces. Once a face/pedestrian/object is detected, the Video Processing Platform extracts the image and additional information.
In the following frames, the Video Processing Platform only performs the tracking operation ─ keeps track of the location of the detected faces/pedestrians/objects. The tracking process is performed on subsequent frames until the next detection, during which Video Processing Platform tries to detect faces/pedestrians/objects again on the entire frame. Tracking requires less computing power than detection because it is not performed on an entire frame but only on the predicted position of the area close to the detected face/pedestrian/object.
The following figure describes detection and tracking on frames at 25 fps (frames per second) video stream:
- The detection time interval is set to 200 ms.
- In this example, tracking is performed on every frame, which means every 40 ms.
- Each time detection is performed, the Video Processing Platform extracts information about the face and its biometric template.
![]()