Configuration
The Video Processing Platform Embedded Stream Processor can be configured in several ways:
- Centralized Edge Stream Management via REST API and Video Processing Platform Station
- Using GUI Client for Linux and Windows
- Locally on device (this section)
To configure the Video Processing Platform Embedded Stream Processor locally you can update settings.yaml file that comes as input of sfe_stream_processor executable.
./sfe_stream_processor /path/to/settings.yaml
The configuration of SFE Stream Processor includes settings of:
- Connection
- Face detection
- Tracking
- Face template extraction
- Face passive liveness
- Face identification
- Messaging
- Cropping
- Full frame
- Solvers
- License
- Logging
SFE Stream Processor configuration can be changed directly by editing the input settings.yaml file or using a simple web UI available by running sfe_settings_server executable.
SFE Stream Processor automatically reloads the configuration when there is a change detected in settings.yaml.
An example settings.yaml is documented here
Connection
MQTT (MQ Telemetry Transport) protocol is used for communication between SFE Stream Processor running on edge device (camera or AI box) and Video Processing Platform running on server/cloud.
See below an example configuration:
connection:
broker_address: 127.0.0.1
broker_port: 1883
client_id: 38-lilin
topic: edge-stream
keep_alive: 60
timeout: 10
tls_enable: false
username: mqtt
password: mqtt
Please find a detailed description of connection parameters below. All connection parameters are related to MQTT.
broker_address
Defines the IP address of a machine where the MQTT broker is running.
- Use the IP address of a server/cloud where the Video Processing Platform platform is running if you are using Video Processing Platform for processing the edge stream.
- Use
127.0.0.1if you want to process the MQTT messages locally. You will also need an MQTT broker running on the device.
You can also use a hostname as broker_address if the DNS is enabled on your edge device.
broker_port
TCP/IP port 1883 is reserved with IANA for use with MQTT. TCP/IP port 8883 is also registered, for using MQTT over SSL. Use this port when TLS is enabled.
client_id
Client ID is a string that identifies the MQTT client connected to an MQTT broker. It should be unique for each camera. If you are processing multiple camera streams on one device, it should be unique for each camera stream. When using the Video Processing Platform for processing the MQTT message stream, the same client ID is used during the registration of a new edge stream.
topic
MQTT topic is a UTF-8 string that the broker uses to filter messages for each connected client.
Topic defines the root topic. The topic for a specific camera is then a combination of “topic” and “client_id” - <connection.topic>/<connection.client_id>, for example, edge-stream/38-lilin.
For integration with the Video Processing Platform, the root topic should be set to edge-stream. This means the topic for a specific camera is edge-stream/<client_id>
keep_alive
MQTT connection keepalive represents the maximum time in seconds allowed to elapse between MQTT protocol packets sent by the client.
timeout
MQTT connection timeout in seconds. It limits how long the client will wait when trying to open a connection to an MQTT server before timing out.
tls_enable
You can enable TLS to encrypt communication between MQTT clients. The MQTT communication is not encrypted by default and it is highly recommended to use TLS, especially in public networks. TLS is required in case of cloud deployment of the Video Processing Platform.
username and password
MQTT supports username/password authentication to restrict access to an MQTT broker.
The MQTT broker used in the Video Processing Platform requires the following username and password:
username: mqtt
password: mqtt
You can set your username and password in the Video Processing Platform RabbitMQ interface running on port 15672, for example:
smartface-platform:15672
Face Detection
This section describes the configuration of face detection.
See below an example configuration:
face_detection:
detection_threshold: 0.06
max_detections: 10
order_by: DetectionConfidence
min_face_size: null
max_face_size: null
detection_threshold
The threshold is used to filter low-confidence detections from processing. Detections below this threshold are not considered in tracking. The valid range is <0.0,1.0> The recommended value is 0.06.
max_detections
Defines the maximum number of faces to be detected, tracked and processed per frame.
order_by
Detected faces can be ordered by FaceSize or DetectionConfidence.
min_face_size
Defines minimal face size for detected faces. Faces with face size below this threshold won’t be processed and won’t be included in the message. The value can be absolute (>1.0, therefore in pixels) or relative to full frame width (<=1.0, therefore face size in pixels /image width in pixels). If not set (null), faces are not filtered by size.
max_face_size
Defines maximal face size for detected faces. Faces with face size above this threshold won’t be processed and won’t be included in the message. The value can be absolute (>1.0, therefore in pixels) or relative to full frame width (<=1.0, therefore face size in pixels /image width in pixels). If not set (null), faces are not filtered by size.
Tracking
This section describes the configuration of tracking.
See below an example configuration:
tracking:
threshold: 0.1
stability: 0.85
max_frames_lost: 25
threshold
Minimal detection confidence threshold for tracked faces. Faces with detection confidence below this threshold are filtered out by tracking and not propagated to landmarks detection and template extraction. The valid range is <0.0,1.0> The recommended value is 0.1.
stability
Stability is used to associate the tracklets with detections using a Kalman filter. Low stability may cause tracking to jump between detections. High Stability may cause more tracklets to be created. The valid range is <0.0,1.0> The recommended value is 0.85.
max_frames_lost
Defines the maximum number of frames to keep lost faces in tracking. max_frames_lost: 25
Face Template Extraction
This section describes the configuration of template extraction.
See below an example configuration:
face_extraction:
enable: true
enable
Enable face template extraction. The face template is used for identification.
If disabled (false), extraction is not performed, and face templates are not included in the FrameData. It means the template extraction has to be performed on the server to enable the identification.
Face Passive Liveness
This section describes the configuration of passive liveness evaluation.
See below an example configuration:
face_liveness_passive:
enable: true
strategy: OnEachExtractedFace
conditions:
- parameter: FaceSize
lower_threshold: 30.0
- parameter: FaceRelativeArea
lower_threshold: 0.009
- parameter: FaceRelativeAreaInImage
lower_threshold: 0.9
- parameter: YawAngle
lower_threshold: -20.0
upper_threshold: 20.0
- parameter: PitchAngle
lower_threshold: -20.0
upper_threshold: 20.0
- parameter: Sharpness
lower_threshold: 0.6
enable
Enable face passive liveness evaluation.
If disabled (false), liveness evaluation is not performed, and liveness score is not included in the FrameData.
strategy
Defines strategy for liveness detection:
OnEachExtractedFace- If enabled, liveness is computed for each extracted faceOnEachIdentifiedFace- If enabled, liveness is computed for each recognized/identified face
conditions
Conditions defining minimal quality of the input face image for reliable liveness/spoof detections. The recommended thresholds are documented at Face Liveness Detection If the conditions are not met liveness score is not computed.
Face Identification
This section describes the configuration of face identification.
See below an example configuration:
face_identification:
enable: true
storage: /root/sfe/records_storage.bin
candidate_count: 1
threshold: 0.40
enable
Enable face identification. If disabled (false), identification is not performed, and the identification results are not included in the FrameData.
storage
Defines the path to the directory on your file system to store the data for identification purposes.
candidate_count
Defines the maximum number of candidates returned from identification.
threshold
Defines the matching score threshold for identified candidates. Candidates with a matching score below this threshold are not considered positive matches and are not returned. The valid range is <0.0,1.0> The recommended value is 0.40.
Messaging
SFE Stream Processor sends messages containing face recognition analytics (FrameData) to the MQTT broker configured in the connection section.
See below an example configuration:
messaging:
enable: true
format: Protobuf
strategy: OnNewAndInterval
interval: 500
allow_empty_messages: false
enable
Enable or disable sending messages from the SFE Stream Processor.
format
Defines the format of the message serialization. Supported message formats are Json, Yaml and Protobuf.
strategy
Defines the messaging strategy. Currently, the OnNewAndInterval strategy is supported. It means the message is sent when a new face is detected or the interval is expired.
interval
Defines the time interval in milliseconds for sending messages. The message is sent at least each <interval> milliseconds.
allow_empty_messages
By default, the message is sent only when:
- a new face is detected or
- at least one face is tracked This parameter enables sending empty messages. It is meant for debugging purposes only. An empty message means there are no detected or tracked faces
Crop image
This section describes the configuration of cropping.
See below an example configuration:
crop:
enable: true
size_extension: 2
max_size: 50.0
image_format: Raw
image_quality: 0.85
enable
Enable sending crop images of detected faces. Crop images can be used for post-processing or storage purposes on the server/cloud.
size_extension
Defines the size of the crop as an extension of the detection bounding box. The crop will be centered on the detection bounding box and the size will be multiplied by this value. Valid values are 0, 1, 2, 3, 4 and 5. You should use the correct value depending on the post-processing required on the server side, for example:
- Template extraction requires
size_extension=2 - Passive liveness detection requires
size extension=5
max_size
Defines the maximum size of the face in the crop area. Once a face is detected and its crop area is calculated using face_size_extension, this value will be used to determine the scale of the crop.
image_format
Specifies the format of the cropped images sent in a message. Supported image formats are Raw, Jpeg and PNG.
image_quality
Image quality for image formats that support compression. The range is from 0.0 for very low quality (high compression ratio) to 1.0 for maximum quality (no compression).
Full frame
This section describes the configuration of full frames.
See below an example configuration:
full_frame:
enable: false
image_width: null
image_height: null
image_format: Raw
image_quality: 0.85
enable
Enable sending full-frame images. Please note sending a full-frame image requires a lot of bandwidth. That is why this parameter should be used for debugging purposes only.
image_width
The width of the full-frame image. If not specified (null), the default width is used.
image_height
The height of the full-frame image. If not specified (null), the default height is used.
image_format
Specifies the format of the full-frame image sent in a message. Supported image formats are Raw, Jpeg and PNG.
image_quality
Image quality for image formats that support compression. The range is from 0.0 for very low quality (high compression ratio) to 1.0 for maximum quality (no compression).
Solvers
This section describes the configuration of solvers.
See below an example configuration:
solvers:
frame_input:
solver: /emmc/plugin/Inno/solver/camera-input.ambarella.solver.0.7.3
parameters: []
frame_output:
solver: null
parameters: []
face_detection:
solver: /emmc/plugin/Inno/solver/face_detect_accurate_mask_w1280h720_perf.ambarella.solver.0.7.3
parameters: []
face_landmarks:
solver: /emmc/plugin/Inno/solver/face_landmarks_0.25_acc.ambarella.solver.0.7.3
parameters: []
face_extraction:
solver: /emmc/plugin/Inno/solver/face_template_extract_accurate_mask_perf.ambarella.solver.0.7.3
parameters: []
face_liveness_passive:
solver: null
parameters: []
For each solver, you can also define solver-specific parameters as an array of name and value pairs. Support solver parameters are documented in SFE Solver.
To apply changes in solver configuration it is required to restart the SFE Stream Processor.
frame_input
Defines the relative or full path to frame input solver.
The frame input solver is responsible for loading the frame data from various video sources.
See also Video Processing Platform Embedded Input and Output Solvers for more information on how to configure input solver properly.
frame_output
For debugging purposes only.
Defines the relative or full path to the frame output solver. Can be used for the output stream annotations.
face_detection
Defines the relative or full path to face detection solver.
face_landmarks
Defines the relative or full path to face landmarks solver.
face_extraction
Defines the relative or full path to face template extraction solver.
face_liveness_passive
Defines the relative or full path to face passive liveness solver.
License
In this section, you can set the license to be used for the initialization of the SFE Stream Processor
See below an example configuration:
license:
data: ewogICAgInZlcnNpb24iOiAiMi4xIiwKICAgI...
To apply changes in License data it is required to restart the SFE Stream Processor.
data
Base64 encoded license data.
The default value is null, which means the license file from the file system or ILICENSE_DATA environment variable is used. For more information, see also Licensing documentation.
Log
This section describes the configuration of logging.
See below an example configuration:
log:
level: Info
path: /emmc/plugin/Inno/log/sfe_stream_processor.log
To apply changes in logging configuration it is required to restart the SFE Stream Processor.
level
Specifies the log level. Supported values are:
Off- logging is turned offError- only error messages are loggedWarn- additionally warning messages are loggedInfo- additionally info messages are loggedDebug- additionally debug messages are loggedTrace- additionally trace messages are logged,
The default log level is Info
path
Defines the path to a log file. When no path is set, standard error (stderr) is used.
By default, no log file path is set.
SFE Stream processor configuration example
# MQTT Connection
connection:
# Address of the MQTT broker server
broker_address: 10.11.82.88
# Port of the MQTT broker server (default: 1883)
broker_port: 1883
# Client ID of the MQTT client, when empty a random UUID will be generated on startup
client_id: 38-lilin
# MQTT root topic path
topic: edge-stream
# Connection keep alive in seconds
keep_alive: 60
# Connection timeout in seconds
timeout: 10
# Enable TLS
tls_enable: false
# Username for authentication
username: mqtt
# Password for authentication
password: mqtt
# Face detection
face_detection:
# The threshold is used to filter low-confidence detections from processing. Detections below this threshold are not considered in tracking.
detection_threshold: 0.06
# Limit the number of faces to be detected
max_detections: 10
# Detected faces are order by (FaceSize, DetectionConfidence)
order_by: DetectionConfidence
# Minimal detectable face size
min_face_size: null
# Maximal detectable face size
max_face_size: null
# Face tracking
tracking:
# Minimal detection confidence threshold for tracked faces. Faces with detection confidence below this threshold are filtered out by tracking and not propagated to landmarks detection and template extraction.
threshold: 0.1
# Stability of tracking
# low stability may cause tracking to jump between detections
# high Stability may cause more tracklets to be created
stability: 0.85
# Maximum number of frames a face can be lost before it is removed from the tracking list
max_frames_lost: 25
# Face extraction
face_extraction:
# Enable face extraction, if disabled identification will not work
enable: true
# Face passive liveness:
face_liveness_passive:
# Enable face passive liveness calculation, if disable liveness score is not calculated
enable: false
# Face liveness strategy
strategy: OnEachExtractedFace
# Liveness conditions for reliable liveness detection
conditions:
# Minimal face size
- parameter: FaceSize
lower_threshold: 30.0
# Minimal face relative area
- parameter: FaceRelativeArea
lower_threshold: 0.009
# Minimal face relative area in image
- parameter: FaceRelativeAreaInImage
lower_threshold: 0.9
# Yaw angle range
- parameter: YawAngle
lower_threshold: -20.0
upper_threshold: 20.0
# Pitch angle range
- parameter: PitchAngle
lower_threshold: -20.0
upper_threshold: 20.0
# Minimal sharpness
- parameter: Sharpness
lower_threshold: 0.6
# Face identification
face_identification:
# Enable face identification
enable: true
# Path to the face database
storage: /emmc/plugin/Inno/records_storage.bin
# Maximum number of candidates to be returned by the identification
candidate_count: 10
# Threshold for face identification, identification confidence must be higher than this value
threshold: 0.40
# Message strategy and format
messaging:
# Enable message publishing
enable: true
# Message format to be used
# Json: Json format
# Protobuf: Protobuf format
# Yaml: Yaml format
format: Protobuf
# Publishing strategy:
# OnNewAndInterval: Publishes a message when a new face is detected and every interval
strategy: OnNewAndInterval
# Publising interval in milliseconds between messages
interval: 250
# Publish a message even when no faces are detected
allow_empty_messages: false
# Include face image in the message
crop:
# Enable face image in message
enable: true
# Border around the face in face width units
size_extension: 2
# Max width of the face image in the message in pixels
max_size: 50.0
# Image format of the face image in the message
# Jpeg: Jpeg format
# Png: Png format
# Raw: Raw BGR format
image_format: Raw
# Defines image quality in case of image format with compression support
image_quality: 0.85
# Include full input frame in the message
full_frame:
# Enable full frame in message
enable: false
# Width of the full frame in the message, if null the original frame width will be used
image_width: null
# Height of the full frame in the message, if null the original frame height will be used
image_height: null
# Image format of the full frame in the message
# Jpeg: Jpeg format
# Png: Png format
# Raw: Raw BGR format
image_format: Raw
# Defines image quality in case of image format with compression support
image_quality: 0.85
# Solvers to be used
solvers:
# Solver used to aquire the input frame
frame_input:
solver: ./solver/gstreamer_input.cpu.solver
parameters:
- name: gst_pipeline
value: "rtspsrc location=rtsp://root:Innovatrics1@192.168.17.40:554/axis-media/media.amp latency=30 ! rtph264depay ! h264parse ! openh264dec ! videorate ! videoconvert ! videoscale ! video/x-raw,format=BGR,framerate=10/1,width=1280,height=720"
- name: gst_width
value: 1280
- name: gst_height
value: 720
# Solver used to output the frame for preview and debugging
frame_output:
solver: null
parameters: []
# Solver used to detect faces
face_detection:
solver: ./solver/face_detect_accurate_mask.onnxrt.solver
parameters:
- name: runtime_provider
value: cpu
- name: intra_threads
value: '6'
- name: inter_threads
value: '1'
# Solver used to detect face landmarks
face_landmarks:
solver: ./solver/face_landmarks_0.25.onnxrt.solver
parameters:
- name: runtime_provider
value: cpu
- name: intra_threads
value: '6'
- name: inter_threads
value: '1'
# Solver used to exract face templates
face_extraction:
solver: ./solver/face_template_extract_accurate_mask.onnxrt.solver
parameters:
- name: runtime_provider
value: cpu
- name: intra_threads
value: '6'
- name: inter_threads
value: '1'
# Solver used to calculate passive liveness score
face_liveness_passive:
solver: ./solver/face_liveness_passive_distant.onnxrt.solver
parameters:
- name: runtime_provider
value: cpu
- name: intra_threads
value: '6'
- name: inter_threads
value: '1'
license:
data: null
log:
level: Info
path: /emmc/plugin/Inno/log/sfe_stream_processor.log
SFE Settings server
You can use the SFE Settings Server to modify the configuration using Web UI. It changes the content of settings.yaml file which comes as an input argument.
You have to configure the IP address and port where the settings UI is available.
See below an example of how to run the SFE Setting Server.
./sfe_settings_server --address 0.0.0.0 --port 8592 --settings-file settings.yaml
Then you can use the following URL (IP address of the camera and specified port) to access and modify the configuration.
10.11.80.38:8592
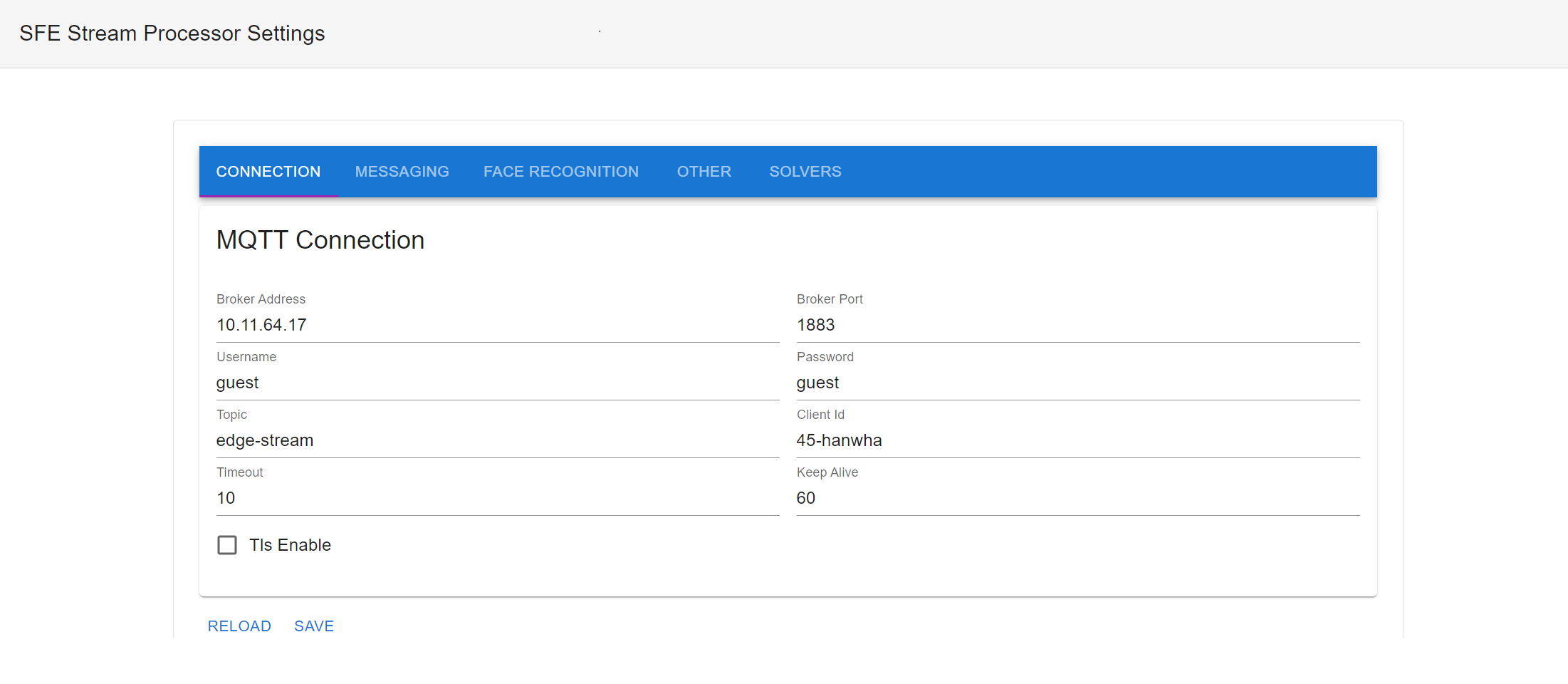
Scroll down and click the Save button to save and apply the changes.
The SFE Stream Processor listens to changes in settings.yaml and reloads the configuration if necessary.
To apply changes in solvers, logging and license configuration it is required to restart the SFE Stream Processor
SFE Settings Server also displays the latest logging information based on the configured log level.
GStreamer pipelines
Generic rules for using GStreamer pipelines
In this article, there are multiple examples of the GStreamer pipeline and they can be used in 2 different ways.
Using gst-launch-1.0
The gst-launch-1.0 tool should be used for pipeline validation. You need to visualize the pipeline output first, then you can pass it to the sfe_stream_processor. If you’re trying to run a Gstreamer pipeline from this article with gst-launch-1.0, you should modify the example pipeline as follows:
$ gst-launch-1.0 <here goes example pipeline of your choice> \
! videoconvert ! xvimagesink
Parts of the modified pipeline:
- first, you prepend gst-launch-1.0
- then you place your pipeline right after the
gst-launch-1.0 videoconvertelement goes right after the example pipeline (converts frames to the correct format for pipeline sink)- the last element is a pipeline sink (recommended is
xvimagesink)
Using sfe_stream_processor
In the SFE stream processor, you have to write down a GStreamer pipeline in settings.yaml file (this is the file the sfe_stream_processor takes as its input). The YAML file contains lots of different fields but here, we focus only on frame_input section:
frame_input:
solver: ./solver/gstreamer_input.cpu.solver
parameters:
- name: gst_pipeline
value: "here goes example pipeline"
- name: gst_width
value: <frame_width>
- name: gst_height
value: <frame_height>
If we consider a specific example:
frame_input:
solver: ./solver/gstreamer_input.cpu.solver
parameters:
- name: gst_pipeline
value: "rtspsrc location=rtsp://root:Innovatrics1@192.168.17.40:554/axis-media/media.amp latency=30 ! rtph264depay ! h264parse ! openh264dec ! videorate ! videoconvert ! videoscale ! video/x-raw,format=BGR,framerate=10/1,width=1280,height=720"
- name: gst_width
value: 1280
- name: gst_height
value: 720
See also GStreamer input solver for more information and parameters.
There are a few rules to follow while designing your pipeline:
- the pipeline MUST convert the video source to BGR format
- width/height properties MUST specify frame resolution going out of your pipeline
- sink elements MUST NOT be specified
- in most cases, the last part of your pipeline should contain
videoconvert ! video/x-raw,format=BGR
Example pipelines
Pipeline using MP4 video file
filesrc location=test.mp4 \
! qtdemux ! h264parse ! avdec_h264 \
! videorate drop-only=true \
! videoconvert ! video/x-raw,format=BGR,framerate=10/1
Pipeline using MP4 video file and Intel VA-API elements
filesrc location=test.mp4 \
! qtdemux ! vaapidecodebin \
! queue leaky=no max-size-buffers=5 max-size-bytes=0 max-size-time=0 \
! vaapipostproc ! videorate \
! video/x-raw,framerate=10/1,width=1280,height=720 \
! queue leaky=no max-size-buffers=5 max-size-bytes=0 max-size-time=0 \
! videoconvert ! video/x-raw,format=BGR
Pipeline using RTSP stream
rtspsrc location=rtsp://aa.bb.cc.dd/strm latency=1 \
! queue ! rtph264depay ! h264parse ! avdec_h264 \
! videorate ! videoconvert ! videoscale \
! video/x-raw,format=BGR,width=1280,height=720,framerate=10/1
Pipeline using USB camera
v4l2src device=/dev/video0 ! video/x-raw,framerate=10/1,width=1280,height=720 \
! videoconvert ! video/x-raw,format=BGR
Note: You may be interested in using another GStreamer tool gst-device-monitor-1.0 that lists all input devices. Simplified example output of this tool run on a laptop with Webcam:
Device found:
name : Integrated_Webcam_HD: Integrate
class : Video/Source
caps : video/x-raw, format=YUY2, width=640, height=480, pixel-aspect-ratio=1/1, framerate=30/1
...
image/jpeg, width=1280, height=720, pixel-aspect-ratio=1/1, framerate=30/1
...
properties:
...
device.subsystem = video4linux
device.product.name = Integrated_Webcam_HD: Integrate
...
device.path = /dev/video0
...
gst-launch-1.0 v4l2src ! ...