Advanced Installation
After an initial installation you might want to work on advanced settings and fine tune your installation to match your exact needs.
The Video Processing Platform can be fine tuned to match your environment and your needs. There are several way to fine tune it, such as:
- enabling GPU usage
- scaling services (Windows / Linux)
- optimalizing camera preview
- optimalizing detection and extraction intervals
GPU Enablement
GPUs (Graphics Processing Units) and CPUs (Central Processing Units) are both essential components of computing, but they excel at different types of tasks due to their design differences.
GPUs are specifically designed to handle parallel tasks efficiently. They consist of thousands of cores that can execute multiple instructions simultaneously. This makes them exceptionally powerful for tasks that can be broken down into smaller parts and processed concurrently, such as the Video Processing Platform processes related to detection, extraction and liveness.
However, despite these advantages, CPUs still remain crucial for overall system operation, managing tasks, and executing complex instructions that GPUs may not handle efficiently. They are versatile and excel in tasks requiring high-speed cache access, branching operations, and managing system resources. Both CPUs and GPUs often work in tandem to optimize performance for various computing tasks.
Services that can run on GPUs tend to have much faster results than on CPUs. If a compatible graphics card is available using it will be very beneficial for performance of your system.
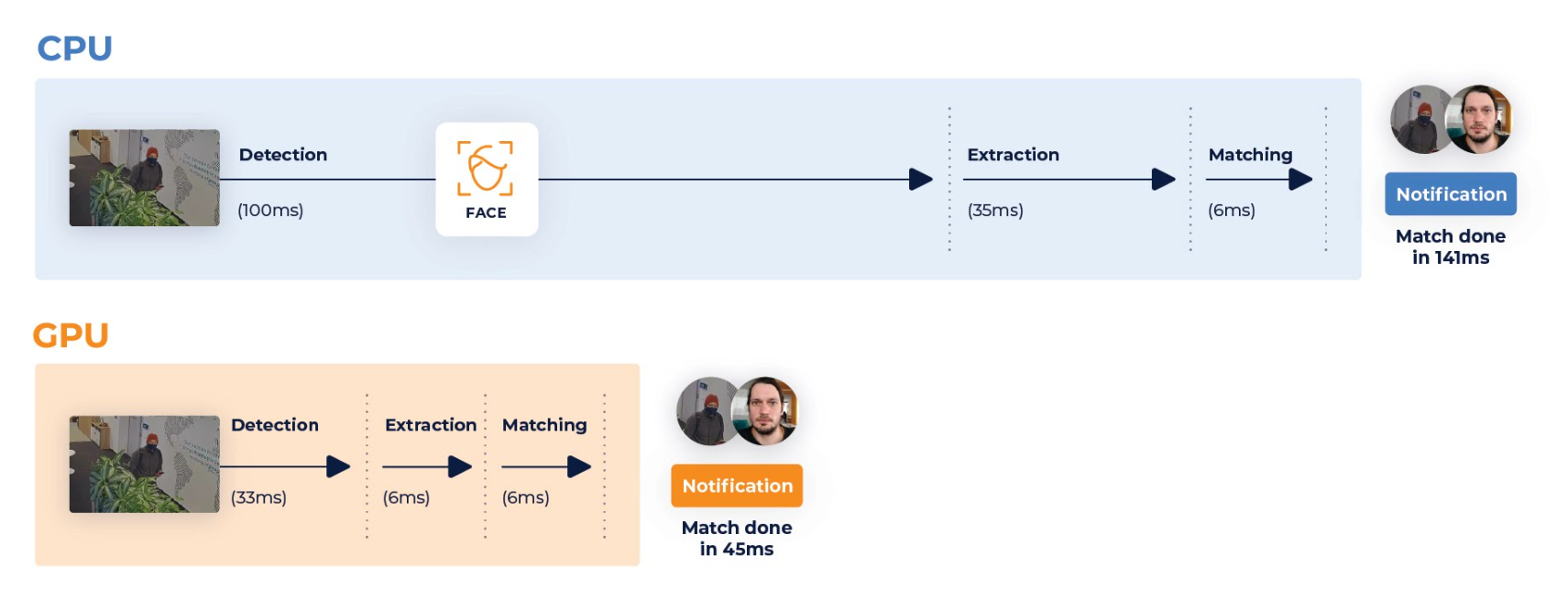
The process to enable GPU differs for Windows and Docker environments:
Enabling GPU on Windows environment
Some services can benefit from GPU acceleration, which can be enabled in services, but also some prerequisites needs to be met on host machine.
To use GPU acceleration, you will need to have the following on the docker host machine:
- NVIDIA GPU compatible with CUDA 11.8
- NVIDIA driver of version >= 520.61
- NVIDIA drivers download page: https://www.nvidia.com/Download/index.aspx
HW decoding
There is no support for HW decoding of video streams in Windows. All streams are decoded using CPU.
Neural Networks processing GPU support
Video Processing Platform is capable of leveraging GPU to speed up biometric operations. We supports only CUDA enabled graphic cards (more VRAM memory the better).
GPU utilization can be configured via configuration files, environment variables and command line arguments. The default configuration section is:
"Gpu": {
"GpuEnabled": false,
"GpuDeviceIndex": 0,
"GpuNeuralRuntime": "Default"
}
The configuration can be set differently for each SF process (service) which enables the configuration to match specific needs of any deployment.
| Property | Value | Descrption |
|---|---|---|
| GpuEnabled | boolean (true, false) | Configures if Gpu should be utilized when neural runtime is set to default. Note that setting this property to true and not having GPU available will cause SF to not start properly |
| GpuDeviceIndex | integer (starting at 0) | Configures which Gpu device should be utilized. This can be used when the machine that runs SF has multiple GPU devices, as a single process and only utilize single Gpu device. Currently only relevant when using Default neural runtime. |
| GpuNeuralRuntime | "Default", "Cuda", "Tensor" | Configures different neural network acceleration runtimes. Will only take effect when GpuEnabled is set to true. Note that runtimes other then default need to be supported by your Gpu device |
During installation on windows the installer asks whether to install Gpu services. If this option is checked, then services with Gpu suffix are registered and configured to utilize Gpu.
Enabling GPU on Docker environment
Some services can benefit from GPU acceleration, which can be enabled in docker compose file, but also some prerequisites needs to be met on host machine.
To use GPU acceleration, you will need to have the following on the docker host machine:
- Nvidia GPU compatible with Cuda 11.8
- Nvidia driver of version >= 520.61
- Nvidia container toolkit https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
HW decoding
To use GPU for HW decoding and face detection for cameras uncomment - runtime: nvidia and - GstPipelineTemplate in docker-compose.yml for camera services sf-cam-*. When using the NVIDIA docker runtime, Video Processing Platform camera processes need gstreamer pipelines as camera source.
A sample camera configuration in the docker-compose.yml file below:
sf-cam-1:
image: ${REGISTRY}sf-cam:${SF_VERSION}
container_name: SFCam1
command: --serviceName SFCam1
ports:
- 30001:${CameraDefaults__PreviewPort}
restart: unless-stopped
environment:
- RabbitMQ__Hostname
- RabbitMQ__Username
- RabbitMQ__Password
- RabbitMQ__Port
- ConnectionStrings__CoreDbContext
- Database__DbEngine
- AppSettings__Log_RollingFile_Enabled=false
- AppSettings__USE_JAEGER_APP_SETTINGS
- JAEGER_AGENT_HOST
- S3Bucket__Endpoint
- S3Bucket__BucketName
- S3Bucket__AccessKey
- S3Bucket__SecretKey
- GstPipelineTemplate
#- Gpu__GpuNeuralRuntime=Tensor
volumes:
- "./iengine.lic:/etc/innovatrics/iengine.lic"
#- "/var/tmp/innovatrics/tensor-rt:/var/tmp/innovatrics/tensor-rt"
runtime: nvidia
Neural Networks processing GPU support
To use support GPU acceleration in remote detector service, extractor service, pedestrian detector service, object detector service or liveness services uncomment environment variable: Gpu__GpuEnabled=true
For specify neural networks runtime what will be used, uncomment environment variable Gpu__GpuNeuralRuntime and set one of the value: Default, Cuda or Tensor.
Tensor value only if your GPU supports tensor runtime.When using Tensor you can uncomment mapping "/var/tmp/innovatrics/tensor-rt:/var/tmp/innovatrics/tensor-rt" to retain TensorRT cache files in the host when container is recreated. This can be helpful as generating cache files is a longer operation which needs to be performed before the first run of the neural network.
An example of a service using the GPU support and the tensor support:
detector:
image: ${REGISTRY}sf-detector:${SF_VERSION}
container_name: SFDetectCpu
restart: unless-stopped
environment:
- RabbitMQ__Hostname
- RabbitMQ__Username
- RabbitMQ__Password
- RabbitMQ__Port
- AppSettings__Log_RollingFile_Enabled=false
- AppSettings__USE_JAEGER_APP_SETTINGS
- JAEGER_AGENT_HOST
- Gpu__GpuEnabled=true
- Gpu__GpuNeuralRuntime=Tensor
volumes:
- "./iengine.lic:/etc/innovatrics/iengine.lic"
- "/var/tmp/innovatrics/tensor-rt:/var/tmp/innovatrics/tensor-rt"
runtime: nvidia
Cloud Deployment
The Video Processing Platform can be used and deployed in the cloud. The cloud installations do not support all the functionalities of an on-premise installation. For users and developers familiar with the Helm Charts we provide our preset configuration at Github.
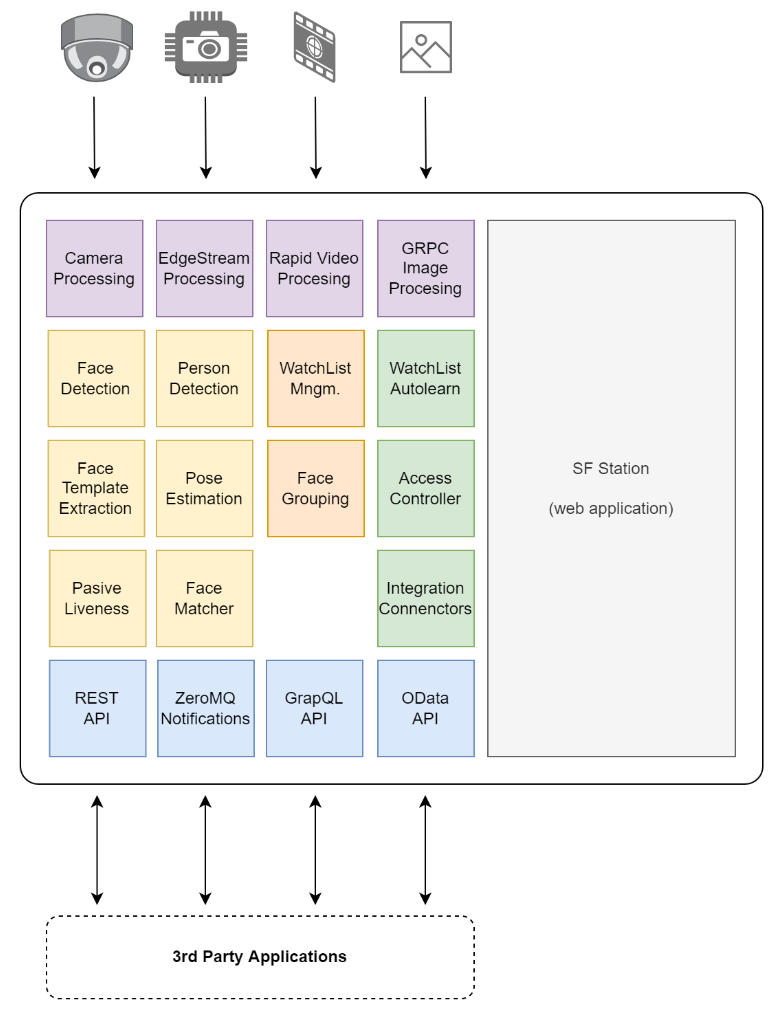
Functionalities of the Video Processing Platform
Currently, the helm chart supports Edge Stream and Lightweight Face Identification System (LFIS) deployments. This means that the RTSP Camera Streams or Rapid Video Investigation are not supported.
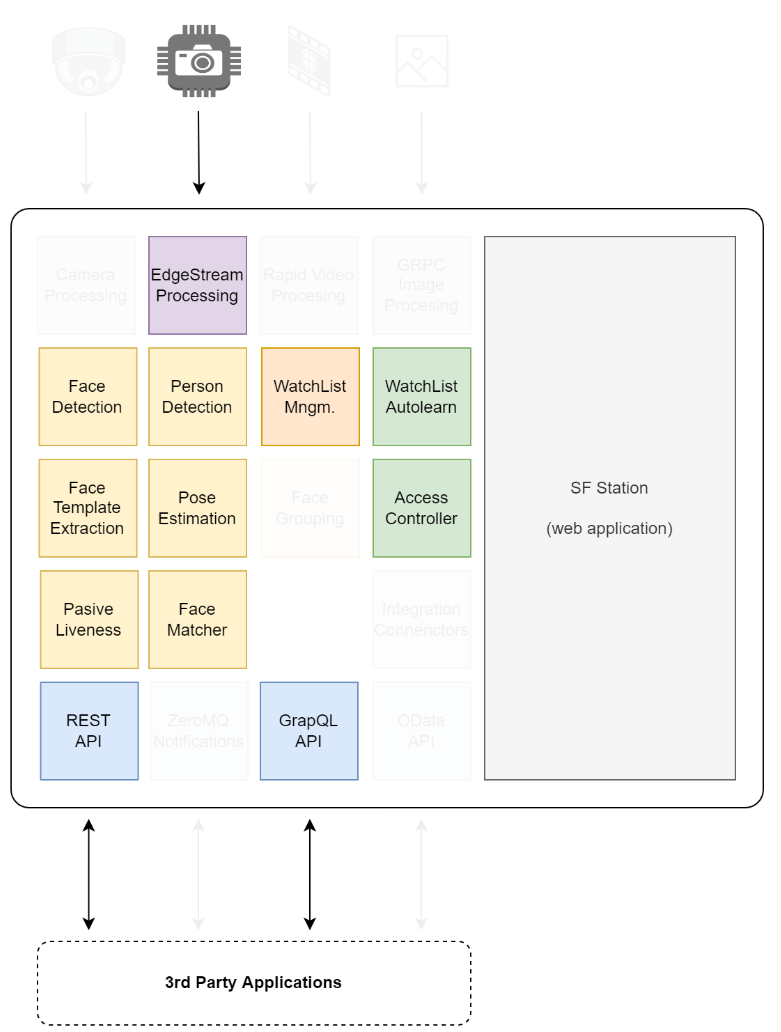
Functionalities of the Video Processing Platform in the Cloud
The cloud deployment is a complex topic. If you would like to know more, please contact us directly.