ID Document Data Extraction - OCR
Optical Character Recognition (OCR) functionality of the Digital Identity Service (DIS) processes the image of identity documents of customer whose identity is verified, and extracts text and image data from those images.
The recognized text data is returned as an object that describes the customer that owns the document. The data are split between those relevant to the “customer” himself and those relevant to the “document” of that customer. The data structure is described in the response of the GET customers API call. Each standard ID document should contain following data:
| ID document data field | Name of the related object in API response |
|---|---|
| Given names | customer.givenNames |
| Surname | customer.surname |
| Full name (some documents state one name field instead of the two above) | customer.fullName |
| Date of birth | customer.dateOfBirth |
| Document number | customer.document.documentNumber |
| Document date of expiry | customer.document.dateOfExpiry |
Each text field is assigned to a category that is universal across all documents, such as “surname”. It is possible to also retrieve the label - name of that text field as stated on the document using the GET metadata API call.
Some text fields, such as dates or gender, are normalized to standard format, so that it is possible to operate with documents of multiple countries using the same logic.
If there is an MRZ field, it is parsed and its information are returned as an alternative value of the text fields. The MRZ field is also used for cross-checking the data from the Visual Inspection Zone (VIZ).
DIS also returns image fields, such as primary face photo, images of signature or fingerprints.
API to request OCR
To perform document OCR, at first the customer and customer’s document entities needs to be created. This is done with the POST customers API call and PUT document API call.
After that, the photos of the ID document pages have to be uploaded - front and back side for ID cards, or just a single page for passport, using the PUT document/pages API call.
The recognized data are retrieved with the GET customers API call.
Definition of Identity Documents supported by Innovatrics
Identity document is an official document that proves person’s identity. This is done by providing person’s face and the name and other details that uniquely identify then.
Data needed to uniquely identify a person:
- face photo
- name (full name whether in one field or split to multiple fields)
- date of the birth
- additional identifiers needed, like personal number, parent’s names, etc.
Data needed for unique ID document:
- document unique number
- date of document expiry (There are existing documents that do not expire, but this practice is now avoided by governments, as the photos need to be updated on the documents regularly to cope with person’s aging. Old documents without expiration can be supported, but may have downsides.)
Dimensions of supported documents:
- TD1 86 x 54 mm
- TD2 105 x 74 mm
- TD3 125 x 88 mm
- non-standardized documents with similar dimensions
Supported Identity Document Types
DIS can support identity documents of the following types:
- Passports
- Identity cards
- Driving licenses
- Foreigner permanent residence cards
- and other cards of similar format containing a photo of the holder
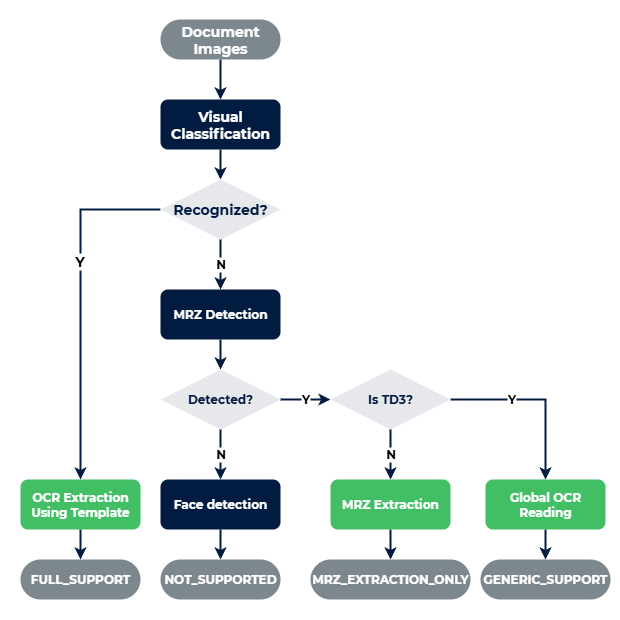
The support for document recognition is in multiple levels:
- NOT_SUPPORTED is for documents where DIS models do not support reading of any text. The document page is searched in such case for a face portrait that can be used for matching with selfie.
- MRZ_EXTRACTION_ONLY, also as Level 1 means that document does not have a specific template, the extraction is done from the data found in the MRZ zone.
- GENERIC_SUPPORT is for documents that have one generic template for multiple documents following the same standard, like passports. BETA: This feature is currently in beta mode and disabled by default. Modify server configuration to enable it.
- FULL_SUPPORT, also as Level 2 means that the document has a dedicated template and extraction of all the data is done in both visual inspection zone (VIZ) and MRZ zone (if present).
For Full Level 2 support, DIS needs to be trained to support each individual document type and its edition. Please check the availability of the required document in the list of supported documents for both levels. In the case an ID document type required for your project is not mentioned in the list, a future version of DIS can be trained to support it. Please contact Innovatrics to request it.
Document Support Levels
The document falls into the support level based on these conditions:
Generic OCR Support for Global Passports
If a passport is not fully supported, a separate model is used to read its visual zone. This one detects the texts in the document and identifies their field type. The greatest benefit of this model compared to MRZ extraction is that the names are not truncated in the visual zone. The following Latin text fields are supported by this model:
- Full name, or Given names and Surname
- Document number
- Personal number
- Date of Birth
- Date of Expiry
- Date of Issue
- Nationality
- Place of birth
- Issuing Authority
Document Classification
Before processing the OCR, the images of the document pages needs to be classified. The classification uses two methods. Visual classification is searching for an image template (among the supported document types) with highest similarity to the processed page. MRZ classification reads the country ISO code from the MRZ zone (if present) and identifies the number of rows and letters in it to identify the document type.
The document page image can be classified as one of these 3 types:
- Front page
- Back page
- Page of an unknown document
When a new page is uploaded, it gets a list of possible classification candidates. Based on these candidates, it is decided, whether it is a front or a back page (or unknown document). If there was an image with same document page type (front/back) uploaded before, it gets replaced. So only the last submitted pages of each type contribute to the classification of the ID document.
When deciding the classification of the document, all the classification candidates are tried to be matched for the same document type between the front page and the back page. A classification pair with the highest sum of confidences decides the classification of the whole document. After OCR there might be an extra check to validate, if the classification was correct based on the extracted texts. If a misclassification was detected, the classification pair with the second highest sum of confidences is chosen for the document classification.
Data normalization
DIS provides a standardized set of text fields, so that documents of different types can be evaluated with the same logic. Text fields such as dates are normalized to ISO format.
To find out which text fields are returned for a specific document type, use the GET metadata API call.
Document authenticity
DIS provides technology to check the authenticity of an identity document, more about it is in the Document Authenticity Evaluation.
Document photo quality check
The document page photo quality check is provided if the corresponding API call is used. It checks if the photo of the document has the correct brightness, sharpness, doesn’t contain hotspots, has enough background borders around the document in the image, and is the correct size.
The document page photo quality check result contains detection confidence and the coordinates of the document in the image.
Image requirements
- The supported image formats are JPEG and PNG
- The document image must be large enough - document card width should be approximately 750 pixels on the image
- The document card edges must be clearly visible and be placed at least 10 px inside the image area
- The image must be sharp enough for the human eye to recognize the text
- There should be no glare on the document card that obscures the text or photo
- The image should not contain objects or backgrounds with visible edges. This can confuse the detection process
- The document should not be a specimen
Example of a sufficient quality document

Example of a not suitable image - the borders around the document are cropped

Further examples of not suitable images due to low quality are in the technical documentation section document page quality.